
Googler insights into product and technology news and our culture.
Discovering hard-to-find books
Tomorrow is the day we said we'd resume scanning in-copyright works with our library partners as part of our initiative to build a card catalog of books with Google Print. We are in the process of resuming scanning (it may take a little time), so you should soon be able to search across more books from our partner libraries at print.google.com. We've already had great success working with publishers directly to add their works to our index through our Publisher Program, and when we add books with publisher permission, we can offer more information and a much richer user experience.
As always, the focus of our library effort is on scanning books that are unique to libraries including many public domain books, orphaned works and out-of-print titles. We're starting with library stacks that mostly contain older and out-of-circulation books, but also some newer books. That said, we want to make all books easier to find, and as we get through the older parts of the libraries we'll start scanning the stacks that house newer books.
These older books are the ones most inaccessible to users, and make up the vast majority of books – a conservative estimate would be 80 percent. Our digital card catalog will let people discover these books through Google search, see their bibliographic information, view short snippets related to their queries (never the full text), and offer them links to places where they can buy the book or find it in a local library.
We think that making books easier to find will be good for authors, publishers, and our users. We're excited to get back to work making a comprehensive, free, full-text card catalog of the world's books a reality. Happy searching!
More video to watch!
You may have seen this funny bit on Google Video, or this one. But hey, we're not only about funny. We've just added a ton more work from sources you might already know, including the list below. (To join this prestigious roster, add your own video through our Upload Program.)
Also starting today, check out new work presented each week by theme on the Google Video Blog - and remember to add the feed from this blog to your Google Reader. Finally, special thanks to all those who provided their work to help make Google Video one of the largest archives of videos on the Web.
Saying thank you with pictures
I recently got married and wanted to send out thank-you notes together with hundreds of photos our guests took using the cameras we put on the tables. Picasa made the process super easy.
In Picasa, select the folder with your pictures. Click the "Gift CD" button and follow the instructions to set your picture size and CD name. To add a nice effect, check the "Include Slideshow" box -- this adds a slideshow presentation that plays when the CD is launched (way more fun than a boring list of files). For recipients who might enjoy saving the photos and viewing them later, check the box to include a copy of Picasa on the CD (it's only 3.9MB). Click "Burn Disc" and Picasa creates the CD.
The finishing touch: a customized photo CD cover. Select a picture and click the "Print" button. Here's what it looks like:
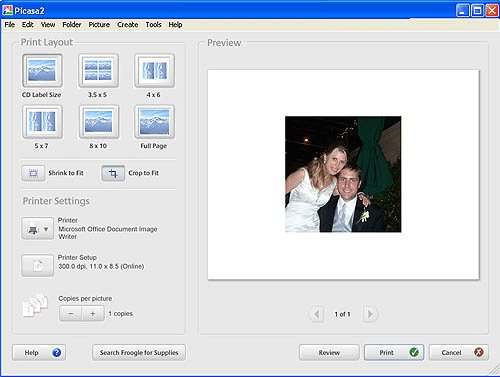
In the top menu, go to to Tools > Options > Printing, select CD Label Size and click OK. Set CD Label as your layout size and print.
You're done -- and now I'm done with my thank-you "work." I'm happy to report the photo CDs were a big hit.
A must-see TV archive
One of the things that absolutely blew me away when I came on board last year as chairman of the Television Academy Foundation was the Archive of American Television, which is an unequaled collection of videotaped interviews with TV legends.
It's a fantastic resource, and so it drove me crazy that the Archive had over 450 interviews -- but no one could view them if they weren’t actually in Southern California. If a student at a school in Cincinnati or Bangkok wanted to learn more about the history of creative or business aspects of the American television industry, these interviews were just not accessible. So I made it a personal goal to find a way to get the Archive online.
And starting today, anyone in the world can go to Google Video and watch complete and uncut Archive interviews and learn directly from the legends and pioneers on how it all happened. How cool is that?
It’s been 30 years since I was in college, but I can honestly say that if I were just starting out in this business, I would be all over the Archive. I’m such a fan of television that I can’t wait to be able to watch some of the interviews on Google Video – with the men and women who inspired me, and continue to inspire me. One of the Archive legends now online is former NBC head Grant Tinker. Grant helped create “Must See TV” on Thursday nights! There’s also Norman Lear, Ted Turner, Steven Bochco, and so many more. The Archive was created to educate, entertain, and inspire future generations. I challenge you to look up your favorite TV show, learn about a favorite star, or discover more about some of the most important news events of the 20th century. I’m thrilled that the Foundation is finally able to introduce some of these interviews to the world, using the world’s most powerful delivery system – Google. Enjoy!
Update: added URL
Rumor of the day
You may have seen stories today reporting on a new product that we're testing, and speculating about our plans. Here's what's really going on. We are testing a new way for content owners to submit their content to Google, which we hope will complement existing methods such as our web crawl and Google Sitemaps. We think it's an exciting product, and we'll let you know when there's more news.
Supporting open source
School is a fantastic place to learn, but what if you could introduce students to open source projects, with real problems to solve, and fantastic developers to work with? We thought that would be a pretty terrific way of spending the summer, and with the help of 40 open source, free software and technology-related groups, that is exactly what we did. We call this project the Summer of Code.
Organizations like Apache and Samba and projects such as Nmap, Gaim and Internet2 took part in this program.
Together with these partners, we chose 400 students from 49 countries to take part - and this from a pool of 8,744 applicants, so clearly there's no shortage of talent. We contributed nearly $2 million to this effort via $4,500 grants to each of the participants (and a $500 donation per student to the participating organizations).
Nmap's lead developer, Fyodor Vaskovich, told us that Summer of Code developers "made major improvements to the Nmap Security Scanner, including a more powerful graphical interface and a next-generation remote operating system detection framework." To that we say: excellent. Here's a partial list of participants and projects, and we even threw together a map so people can see how global this program was.
Now that summer is over, we've got a new thing going. Today at the Oregon Governor's office in Salem, we're announcing our support of an open source initiative which two men, Bart Massey and Scott Kveton, at two schools, Oregon State University and Portland State University, have worked very hard to create. Over the last few years, they have collaborated to encourage open source software and hardware development, develop academic curricula and provide computing infrastructure to open source projects worldwide. We're pleased to be able to support their efforts with a donation of $350,000. Here's the official press release about this fantastic project.
Guess what just turned 34?
It's difficult to pin down the exact origin of email, but in October 1971, an engineer named Ray Tomlinson chose the '@' symbol for email addresses and wrote software to send the first network email.
At the time, it must not have seemed very important – nobody bothered to save that first message or even record the exact date. I've always thought that it would be fun to witness a little bit of history like that – to be there when something important happened. That's part of what drove me to join a little no-name startup named Google, and it's why I was excited when I was given a chance to create a new email product, now called Gmail.
Of course that wasn't the only reason why I wanted to build Gmail. I rely on email, a lot, but it just wasn't working for me. My email was a mess. Important messages were hopelessly buried, and conversations were a jumble; sometimes four different people would all reply to the same message with the same answer because they didn't notice the earlier replies. I couldn't always get to my email because it was stuck on one computer, and web interfaces were unbearably clunky. And I had spam. A lot of it. With Gmail I got the opportunity to change email – to build something that would work for me, not against me.
We had a lot of ideas, but first we spent a lot of time talking to all kinds of people about their email. They let us watch over their shoulders and helped us really understand how they use email and what they need from it. We didn't want to simply bolt new features onto old interfaces. We needed to rethink email, but at the same time we needed to respect that email already had over 30 years of history, thousands of existing programs, and nearly a billion users. So we started by learning which features were most important, and which problems were most aggravating. We also realized that solving everyone's problems was too big of a challenge for the first release. It would be better to build a product that a lot of people love, than one that everyone tolerates, and so that was our goal.
On April 1, 2004, we rolled out the first release of Gmail. It immediately became known for giving away 1000 MB of storage, while the others only offered 4 MB, as they had for many years. We didn't do that just for the attention (although we certainly got our share). It's just part of our philosophy. We always want to do as much as we can for our users, and so if we can make something free, we will.
But storage was only the most obvious difference, and our other improvements were just as important. Gmail included a quick and accurate search. It introduced powerful new concepts to organize email, such as the conversation view (so now I can finally see all those replies at once). It provided a fast and dynamic interface from web browsers everywhere, popularizing the techniques that have since become known as AJAX.
This interface included many important features not commonly found on the web at that time, such as email address auto-completion, a slick spell-checker, keyboard shortcuts, and pages that update instantly. It included a smart spam filter to get rid of junk mail. Finally, we made an important new promise: you can keep your Gmail address and all of your email, even if you someday decide that Gmail is not for you. Cell phone owners already have the right to keep their old phone number when switching to a new provider, and you should have that same freedom with email. To ensure this freedom, Gmail provides, for free, both email forwarding and POP download of all your mail. Many services are now beginning to include other Gmail innovations; we hope that some day they will also be willing to include this one.
Of course, the launch was just the beginning, and we're still busy improving Gmail. We keep increasing free storage (2656 MB and counting), we offer the interface in 38 languages, and we now have features such as auto-save drafts, so that you don't accidentally lose that half-written message. We know that Gmail isn’t quite right for everyone yet. We’re working on that too – there’s still more we can do for the folder-lovers and devout-deleters out there. But wait, there’s more! :) We also have a new batch of exciting innovations on the way that we hope will shake things up again and make Gmail even better for even more people.
I'm proud of what we've done so far, and am excited about our future plans for Gmail. So celebrate how far email has come by joining its fun future.
Why we believe in Google Print
We've been asked recently why we're so determined to pursue Google Print, even though it has drawn industry opposition in the form of two lawsuits, the most recent coming today from several members of the American Association of Publishers. The answer is that this program, which will make millions of books easier for everyone in the world to find, is crucial to our company's mission. We're dedicated to helping the world find information, and there's too much information in books that cannot yet be found online. We think you should be able to search through every word of every book ever written, and come away with a list of relevant books to buy or find at your local library. We aim to make that happen, but to do so we'll need to build and maintain an index containing all this information.
It's no surprise that this idea makes some publishers nervous, even though they can easily remove their books from the program at any time. The history of technology is replete with advances that first met wide opposition, later found wide acceptance, and finally were widely regarded as having been inevitable all along. In 1982, for instance, the president of the Motion Picture Association of America famously told a Congressional panel that "the VCR is to the American film producer and the American public as the Boston Strangler is to the woman home alone." But Sony, makers of the original Betamax, stood its ground, the Supreme Court ruled that copying a TV show to watch it later was legal, and today videotapes and DVDs produce the lion's share of the film industry's revenue.
We expect Google Print will follow a similar storyline. We believe that our product is legal (see Eric Schmidt's recent op-ed), that the courts will vindicate this position, and that the industry will come to embrace Google Print's considerable benefits. Even today, despite its lawsuit, the AAP itself recognizes this potential. The Google Print Library Program, AAP president Pat Schroeder said this morning, "could help many authors get more exposure and maybe even sell more books.” We look forward to the day that the program's opponents marvel at the fact that they actually tried to stop an innovation that, by making books as easy to find as web pages, brought their works to the attention of a vast new global audience.
The point of Google Print
You may have read about the AAP's lawsuit announced today which objects to Google Print. We'll post our comments about that soon. Meanwhile, we offer this commentary from Eric Schmidt. It ran on the op-ed page of yesterday's Wall Street Journal, and we are reprinting it in full with that paper's permission.
Books of Revelation
By Eric Schmidt
The Wall Street Journal
October 18, 2005
Imagine sitting at your computer and, in less than a second, searching the full text of every book ever written. Imagine an historian being able to instantly find every book that mentions the Battle of Algiers. Imagine a high school student in Bangladesh discovering an out-of-print author held only in a library in Ann Arbor. Imagine one giant electronic card catalog that makes all the world's books discoverable with just a few keystrokes by anyone, anywhere, anytime.
That's the vision behind Google Print, a program we introduced last fall to help users search through the oceans of information contained in the world's books. Recently, some members of the publishing industry who believe this program violates copyright law have been fighting to stop it. We respectfully disagree with their conclusions, on both the meaning of the law and the spirit of a program which, in fact, will enhance the value of each copyright. Here's why.
Google's job is to help people find information. Google Print's job is to make it easier for people to find books. When you do a Google search, your results now include pointers to those books whose contents, stored in the Google Print index, contain your search terms. For many books, these results will, like an ordinary card catalog, contain basic bibliographic information and, at most, a few lines of text where your search terms appear.
We show more than this basic information only if a book is in the public domain, or if the copyright owner has explicitly allowed it by adding this title to the Publisher Program (most major U.S. and U.K. publishers have signed up). We refer people who discover books through Google Print to online retailers, but we don't make a penny on referrals. We also don't place ads on Google Print pages for books from our Library Project, and we do so for books in our Publishing Program only with the permission of publishers, who receive the majority of the resulting revenue. Any copyright holder can easily exclude their titles from Google Print -- no lawsuit is required.
This policy is entirely in keeping with our main Web search engine. In order to guide users to the information they're looking for, we copy and index all the Web sites we find. If we didn't, a useful search engine would be impossible, and the same dynamic applies to the Google Print Library Project. By most estimates, less than 20% of books are in print, and only around 20% of titles, according to the Online Computer Library Center, are in the public domain. This leaves a startling 60% of all books that publishers are unlikely to be able to add to our program and readers are unlikely to find. Only by physically scanning and indexing every word of the extraordinary collections of our partner libraries at Michigan, Stanford, Oxford, the New York Public Library and Harvard can we make all these lost titles discoverable with the level of comprehensiveness that will make Google Print a world-changing resource. But just as any Web site owner who doesn't want to be included in our main search index is welcome to exclude pages from his site, copyright-holders are free to send us a list of titles that they don't want included in the Google Print index.
For some, this isn't enough. The program's critics maintain that any use of their books requires their permission. We have the utmost respect for the intellectual and creative effort that lies behind every grant of copyright. Copyright law, however, is all about which uses require permission and which don't; and we believe (and have structured Google Print to ensure) that the use we make of books we scan through the Library Project is consistent with the Copyright Act, whose "fair use" balancing of the rights of copyright-holders with the public benefits of free expression and innovation allows a wide range of activity, from book quotations in reviews to parodies of pop songs -- all without copyright-holder permission.
Even those critics who understand that copyright law is not absolute argue that making a full copy of a given work, even just to index it, can never constitute fair use. If this were so, you wouldn't be able to record a TV show to watch it later or use a search engine that indexes billions of Web pages. The aim of the Copyright Act is to protect and enhance the value of creative works in order to encourage more of them -- in this case, to ensure that authors write and publishers publish. We find it difficult to believe that authors will stop writing books because Google Print makes them easier to find, or that publishers will stop selling books because Google Print might increase their sales.
Indeed, some of Google Print's primary beneficiaries will be publishers and authors themselves. Backlist titles comprise the vast majority of books in print and a large portion of many publishers' profits, but just a fraction of their marketing budgets. Google Print will allow those titles to live forever, just one search away from being found and purchased. Some authors are already seeing the benefits. When Cardinal Ratzinger became pope, millions of people who searched his name saw the Google Print listing for his book "In the Beginning" (Wm. B. Eerdmans) in their results. Thousands of them looked at a page or two from the book; clicks on the title's "Buy this Book" links increased tenfold.
That's the heart of the Google Print mission. Imagine the cultural impact of putting tens of millions of previously inaccessible volumes into one vast index, every word of which is searchable by anyone, rich and poor, urban and rural, First World and Third, en toute langue -- and all, of course, entirely for free. How many users will find, and then buy, books they never could have discovered any other way? How many out-of-print and backlist titles will find new and renewed sales life? How many future authors will make a living through their words solely because the Internet has made it so much easier for a scattered audience to find them? This egalitarianism of information dispersal is precisely what the Web is best at; precisely what leads to powerful new business models for the creative community; precisely what copyright law is ultimately intended to support; and, together with our partners, precisely what we hope, and expect, to accomplish with Google Print.
Mr. Schmidt is CEO of Google.
We get letters (3)
This just in: Walid Elias Kai, a Ph.D. in search engine marketing, is, it must be said, an avid fan of our company. Dr. Kai, who is Lebanese, and his Swedish wife Carol live in Kalmar, Sweden, where their son was born on September 12. His name? Oliver Google Kai.
About this choice, Dr. Kai writes, "When we first knew that my wife Carol is pregnant, I said, 'we will name our child Google.' Everyone laughed and did not take me seriously. My brother said, 'Yeah, name the next one yahoo fuji nikon." And then, says Dr. Kai, the day came to make the baby official in the Swedish Registry. "I was with my friend Magnus Foss and my wife Carol, and I said yes, GOOGLE KAI. Carol knew how serious I am – she knows how much I adore Google services."
Clearly not one to shy away from a unique moniker, Dr. Kai also tells us that in the Lebanese tradition both parents have a name related to the child. "All our friends and families are calling us Abou Google (Google's father) and Emm Google (Google's mother)."
Of course, there's a website devoted to young Mr. Kai. We wish him long life and good health, and hope his schoolmates aren't too hard on him.
Our ongoing privacy efforts
We updated our privacy policy today. We know privacy is important to our users, and it's important to us, too. That's why we work hard to let people know how we collect and use personal information to provide our services. A clearly written privacy policy is part of this effort. In this update, most of the terms are the same, but there are two important differences:
First, we created a short, one-page "highlights" notice summarizing our privacy practices. We hope this is easy to digest and understand at a glance. Second, we provided even more detail about our privacy practices in the full-text privacy policy and lots more detail in the accompanying FAQs. The goal of both is to help you make informed choices about using our services.
Designing privacy protection and user choice into Google products is an ongoing effort. Please let us know how we're doing.
More Firefox-Toolbar synchronicity
If you’ve been holding off on upgrading to Firefox 1.5 Beta 2 because you’d miss out on great toolbar features like Suggest and Spell Check, then wait no more! The latest version of the Google Toolbar is fully compatible with the newest rev of Firefox.
Financial reporting: the alphabet soup
Warning: Financial reporting minutiae below. Proceed with caution.
We're going to provide a bit more information with our October 20 earnings announcement. In this and future announcements, we're going to include a so-called pro-forma, or non-GAAP, diluted earnings per share (EPS) number as a supplement to our GAAP EPS number.
In the past, we've only provided GAAP EPS. But because Wall Street analysts typically estimate and describe our results with non-GAAP EPS numbers, that resulted in some confusing apples-to-oranges analyses of our results. (By the way, we review non-GAAP results when we analyze our own performance.) By providing both, we hope it will be easier to understand our results.
Now, if you’ve got your green eyeshade handy, read on. What follows is in accountant-speak.
Earnings per share is calculated by dividing profit (net income) by the number of outstanding shares. That's GAAP. To compute our non-GAAP EPS, we’ll add back to our net income things such as charges for stock-based compensation. (Before adding back stock-based compensation – or other certain charges – we’ll factor in related taxes. What does that mean? When we add back a charge, we subtract the tax benefit related to it that we would get under GAAP accounting. In other words, in the non-GAAP calculation we don't want to include the GAAP tax benefit.) After tax-affecting the charges and then adding them back to net income, we'll take that sum, divide it by outstanding shares and come up with our non-GAAP EPS number.
To illustrate all of this with a fictitious example, let's assume these imaginary data points:
- GAAP net income - $300 million
- Stock-based compensation charge - $100 million (note that other charges in addition to stock-based compensation may be excluded from the computation and presentation of our non-GAAP results as appropriate in the future)
- Tax affect of stock based compensation charge - $35 million
- Shares outstanding for Google - 600 million
$300,000,000 / 600,000,000 = $0.50Now, to get the non-GAAP EPS, we would:
- Subtract the $35 million tax affect from the $100 million stock-based compensation charge to arrive at $65 million
- Add that $65 million to the $300 million GAAP net income for a new, non-GAAP net income of $365 million
- Divide $365 million by 600 million shares outstanding and get a non-GAAP EPS of $0.61.
($300,000,000 + ($100,000,000 - $35,000,000)) / 600,000,000 = $0.61As if this weren't complicated enough, we should note that most, if not all, analysts have historically computed our non-GAAP earnings by adding stock-based compensation to net income without tax-affecting the charge. As a result, when we provide our non-GAAP EPS number, we may be adding back less to compute our non-GAAP earnings than will most of the analysts.
Using the same set of imaginary numbers, analysts might, for example:
- Add the full $100 million stock-based compensation charge to the GAAP net income of $300 million and arrive at their non-GAAP net income of $400 million
- Divide that by outstanding shares and arrive at non-GAAP EPS (for the fictitious example, $0.67 per share)
($300,000,000 + $100,000,000) / 600,000,000 = $0.67Congratulations to those of you who were able to make it this far. We're sorry for the density, but this is dense stuff and we've got to be comprehensive in our explanation of it.
About Google.org
When we told prospective shareholders about Google and how we wanted to do business, we said that we hoped our philanthropic efforts could some day have a greater impact than Google itself. We committed one percent of our profits and equity toward that vision. We’ve looked closely at how those resources can have the greatest impact and found that there are many creative and effective ways to make a difference. So we’ve taken time to investigate, learn and imagine. And while we are still actively engaged in the learning process, we’ve made enough progress that we thought it was a good time to give an update on our plans.
As our founders said in our 2004 annual report, we’re taking a broad approach. We’re calling the umbrella under which we’re putting all of these efforts Google.org. It will include the work of the Google Foundation, some of Google’s own projects, as well as partnerships and contributions to for-profit and non-profit entities. Here are some things we're already working on:
We established the Google Foundation, funded it with $90 million and have made a few initial commitments. We've contributed $5 million to support Acumen Fund, a non-profit venture fund that invests in market-based solutions to global poverty. Acumen Fund supports entrepreneurial approaches to delivering affordable goods and services for the 4 billion people in the world who live on less than $4 a day.
We’re also working with TechnoServe to build small businesses that create jobs and promote economic growth in the developing world. With TechnoServe, we are funding an entrepreneurship development program in Ghana that includes a business plan competition and seed capital for the winners to build their businesses.
In addition, we are working with Alix Zwane and Edward Miguel of UC Berkeley and Michael Kremer of Harvard University to support research in western Kenya to identify ways to prevent child deaths caused by poor water quality.
Google.org also includes projects we manage on our own, using Google talent, technology and other resources. An example is the Google Grants program, which gives free advertising to selected nonprofits. To date, Google Grants has donated $33 million in advertising to more than 850 nonprofit organizations in 10 countries.
Current Google Grants participants include:
Make-a-Wish Foundation - grants the wishes of children with life-threatening medical conditions. More than 25 percent of their online donations are made as a result of their Google ads.
Doctors Without Borders - delivers emergency medical aid to people affected by armed conflict, epidemics, disasters, and exclusion from health care in nearly 70 countries. Google Grants has assisted them with recruiting experienced doctors and nurses for their field programs, which has helped them increase applications by 30 percent this year.
Grameen Foundation USA - uses microfinance and innovative technology to help the world's poorest people escape poverty. Google Grants has helped them attract donors and broaden their newsletter subscriber base.
With Google.org, we’ll also support entities with strong social missions which use market-based solutions for sustainable economic development. One example is our recent donation of $2 million to the One Laptop Per Child program.
While the results we get are more important than the amount of money we give, we want to be clear about how we’re going to keep our “one percent” commitments. There are two parts: equity and profit. For the one percent of equity, we have committed one percent of the outstanding shares that resulted from our initial public offering – 3 million shares. We’re going to donate and invest this amount over a period of as much as 20 years. Because it is based on stock, the dollar value of this commitment will rise and fall with our stock price
We’ll follow through on the other commitment – one percent of profit – by taking one percent of each year’s profits and donating and investing that too. Our first step in meeting these commitments includes a $90 million cash donation to the Google Foundation and a commitment of up to $175 million over three years across our other Google.org efforts. We don’t expect to make further donations to the Foundation for the foreseeable future.
As Larry and Sergey said in their Founders’ Letter, “We hope someday this institution may eclipse Google itself in terms of overall world impact by ambitiously applying innovation and significant resources to the world's problems."
We feel fortunate to have the opportunity to contribute our resources, talent, energy, and passion helping to solve some of the world’s most pressing problems. We will provide you with updates as our work progresses.
Bird flu basics
As flu season approaches, there's been a lot of talk about bird flu. I thought I'd try to clarify some of the issues and misconceptions around this illness. I keep up with news on this and other emerging diseases in a number of ways, including Pro-MED, which is produced by the Federation of American Scientists, and the World Health Organization site. You can also read lots more at the CDC site, especially here.
Bird (avian) flu is an influenza virus type A that normally infects birds, but can also infect pigs and other animals. Wild birds, the natural hosts, normally don't get sick from this virus, but domestic animals such as chickens and turkeys can be severely affected severely. Humans, meanwhile, can be infected with influenza types A, B, and C.
Genetic changes and sharing (the closest thing viruses have to sex) can occur under certain circumstances such as in crowded conditions where poultry, pigs, and people live in close quarters. This change can allow a virus to become much more infectious to humans and more easily transmitted from person to person. And this is where a "pandemic" comes in: it's a worldwide outbreak of a new influenza A virus between humans, while epidemics tend to be seasonal, involving viruses that already exist.
For you history buffs, previous pandemics include:
1918-19: Spanish flu. Caused more than 500,000 deaths in the U.S., and 50 million worldwide.
1957-58: Asian flu. 70,000 deaths in the U.S.
1968-69. Hong Kong flu. 34,000 deaths in the U.S.
Both the 1957-58 and 1968-69 pandemics were caused by viruses containing a combination of genes from a human and an avian influenza virus. It may be reassuring to note that the number of deaths has decreased with each pandemic, possibly due to better supportive medical care.
The avian flu's jump to humans was first detected in 1997, although all the human deaths reported so far (about 60 since 2003) have been due to transmission from animals to humans. There has been more concern recently because the virus has been detected in migratory birds which can't be caught and killed - and which may carry the virus to Europe and Africa within the next two migratory seasons.
The consensus is that although it's possible an avian flu epidemic may occur, no one can predict if it will take place in weeks or years. It all depends on when that genetic shift (from birds to humans) takes place.
There has been no detection of this virus in the U.S. It is possible for travelers to be infected, but most of the cases in humans have been in those with closer contact to birds than a casual traveler has. Since the infection occurs via fecal-oral route, to reduce your risk while traveling, avoid bird markets, zoos, and areas in parks, etc. with high concentrations of bird feces.
Countries that are the most vulnerable to this flu are Indonesia, Vietnam, and Cambodia, due to their high concentration of bird markets. Other areas involved are Thailand, China (south and north), Tibet, Russia, Kazakhstan, and Mongolia. For an update on outbreaks before you travel, check the CDC info for southeast Asia and east Asia.
Symptoms of bird flu in humans have ranged from typical flu-like symptoms (fever, cough, sore throat, muscle aches) to eye infections and pneumonia. If you feel you've been exposed, there are a couple of treatment recommendations available today that you may want to discuss with your doctor. Until these are tested in a pandemic, however, their true efficacy is unknown. There are currently no vaccines available, but many companies are working on them.
Bottom line: For now, avian flu is just a "virus of interest" to medical researchers. Of course, you should always consult with your own doctor about any medical conditions or risks that concern you.
The Green Goddess beckons
Another of our chef candidates has come, cooked, and left us with this tangy offering. (Previous recipes are here.)
Green Goddess Dressing
1 bunch green onion, ends trimmed
10 sprigs parsley, stems removed
6 sprigs fresh thyme
2 tsp. dry tarragon
5 sprigs fresh dill
5 anchovy fillets
1 c. mayo
3/4 c. sour cream
3/4 c. white or red wine vinegar
1 T. sugar
2 tsp. salt
1 tsp. ground black pepper
2-3 cloves garlic
Throw all ingredients in a blender (preferably rinsed of margarita residue), and blend, blend, blend. If you've got time, let it sit overnight - this helps marry the flavors and enhances the tarragon.
Transfer the dressing, rinse blender well and resume margaritas while waiting to serve Green Goddess on your favorite salad, as a veggie dip, or as a sauce for fish or chicken. If refrigerated it will last up to a week or more.
Feed the world
So we've added a new experiment to Google Labs: Google Reader, a service we hope helps you spend more time reading what's important to you (or is, if you'd prefer, nicely diverting). The Reader team is excited to begin iterating in public, and now that Jason Shellen's announced it at Web 2.0 we're excited to get your feedback on this early-stage effort.
We often get asked how anyone's supposed to keep up with the firehose of stuff launched from the web's spigot, so we're offering Reader as a way to help. Like the Personalized Homepage, it's a part of Google's ongoing effort to bring together personalized web content to make information more relevant to users.
And, because I rarely get a forum like this, I'd personally like to thank Google for being able to participate in building Reader with the sorts of accomplished engineers who help keep these web bits pretty interesting. (Waves to Search, Gmail, Maps, Print, News, Suggest, etc.) Thankfully, we're not alone -- everyone involved from corporate entities to thousands of independent developers seem to be focused on lowering the barrier to entry for actually making feeds useful.
For a quick intro to Reader, take the tour, or just get started. I'd make recommendations from my starred items, but a quick scan reveals "still waters running deep" isn't me - I keep my item pool filled with snark (Gawker) or techno-fetishism (Engadget, I'm looking at you).
So go to Google Labs and give it a try. If you're interested in making Reader better, please let us know, as we plan on keeping the experiment alive and kicking as long as there is stuff being syndicated.
Google goes to Washington
It seems that policymaking and regulatory activity in Washington, D.C. affect Google and our users more every day. It’s important to be involved - to participate in the policy process and contribute to the debates that inform it. So we’ve opened up a shop there. The first member of our Washington team is Alan Davidson, a veteran thinker and advocate for issues we care about.
Our mission in Washington boils down to this: Defend the Internet as a free and open platform for information, communication and innovation. OK, that sounds a little high and mighty, so let me break it down into something a bit wonkier with a sampling of the U.S. policy issues we’re working on:
Net neutrality. As voice, video, and data rapidly converge, Congress is rewriting U.S. telecommunications laws and deregulating broadband connectivity, which is largely a good thing. But in a country where most citizens have only one or two viable broadband options, there are real dangers for the Internet: Should network operators be able to block their customers from reaching competing websites and services (such as Internet voice calls and video-on-demand)? Should they be able to speed up their own sites and services, while degrading those offered by competitors? Should an innovator with a new online service or application be forced to get permission from each broadband cable and DSL provider before rolling it out? Or, if that’s not blunt enough for you, what’s better: [a] Centralized control by network operators, or [b] free user choice on the decentralized, open, and astoundingly successful end-to-end Internet? (Hint: It’s not [a].)
Copyrights and fair use. Google believes in protecting copyrights while maintaining strong, viable fair use rights in this new digital age. We support efforts by the U.S. Copyright Office to facilitate the use of orphan works (works whose rights-holders can’t be found), while fully respecting the interests of creators. We applauded the Supreme Court’s carefully calibrated decision in the Grokster case, but worked to defeat legislation that would have created new forms of liability for neutral technologies and services like Google.
Intermediary liability. As a search engine, Google crawls the Internet, gathering information everywhere we can find it. We’re a neutral tool that allows users to find information posted by others – like a continuously updated table of contents for the Internet. Not surprisingly, we don’t believe the Internet works well if intermediaries and ISPs are held liable for things created by others but made searchable through us. That’s why Google will continue to oppose efforts to force us to block or limit lawful speech; instead, we focus on providing users the information, tools, and features (such as SafeSearch) they need to protect themselves online.
This is just a taste. We’re also engaged in policy debates over privacy and spyware, trademark dilution, patent law reform, voice-over-Internet-protocol (VOIP) regulation, and more. The Internet policy world is fluid, so our priorities will surely morph over time. And, of course, Google is a global company. In a future post, we’ll introduce you to some of the policy issues we’re confronting outside the U.S.
How I got to Google, ch. 1
-- via craigslist, and thanks for asking. Our engineers, though, tend to come by more varied, and occasionally odder, routes. Some get recruited out of grad school, or by friends or former colleagues. Others just send their resumes to jobs@google.com. For a few engineers, though, the path has been more interesting. Peter Bradshaw, for instance, built “a music playing system based on printed cards with barcodes and webcams. Includes lego!” (No, I don’t know what that means, either.) Over the next few weeks, we’re going to post some of their stories.
Like this one, from Systems Administrator Aaron Joyner:

My story started when I came into work one morning and was unable to look up something on Google. Being the sysadmin for my company at the time, it was my responsibility to resolve the problem, so I started poking around. It turned out that our DNS server [ed: all the jargony stuff you'll hear in this anecdote refers to the software that websites use to connect and talk to each other] was returning an error when trying to look up google.com, specifically a server failure error. Just as I’d convinced myself that it wasn't our problem but Google’s, the problem suddenly resolved itself. I promptly forgot about it and went back to my regular work.
But then I came in the next morning and had exactly the same problem, so I started looking at Google's DNS responses very closely. It became clear that the specific combination of delegations and glue records they were returning [ed: see note above] would result in an eventual error approximately once per day, and this would then take it about five minutes to give up and try again. Not entirely convinced that I should point the finger at Google yet, I posted a message to my local Linux Users Group asking if anyone had had problems with resolving google.com addresses and got a couple "Yeah, I did have a problem like that once recently" responses.
Thus reinforced, I headed over to Google.com, found the "Contact Us" page and the "Report a problem" link, chunked in a brief problem description and a link to the archived copy of the long technical description from that same mailing list thread, and thought to myself, "Gee, I'll never hear about that again." But then one afternoon a week later I get an email that said, basically, "We've received your problem report, and forwarded it on to the appropriate department, if they need any further information they’ll contact you. Thanks." Again, I thought, "Gee, how nice. I'll never hear about that again."
But that evening I got an email from Dave Presotto (the guy who wrote the DNS server for Plan9) saying that he was looking into it and would get back to me. Forty-five minutes later I got another email, this one describing how he believed they had accidentally fixed the problem earlier in the week due to general code cleanup, and asking what I thought of the solution. After I recovered my senses and stopped bouncing around the room, I had a few email exchanges with Dave, in the course of which I asked casually if they needed any good sysadmins out in Mountain View. He referred me, and the rest is history.
A Friday visit to the database of intentions
Over the past few years I’ve made at least a dozen 90-minute treks from my forested perch at the north end of San Francisco Bay down to the Googleplex, which sits at the heart of Silicon Valley. The reason? I was writing a book, and Google was a major part of the story. I always enjoyed the drive, I’d go down to interview the founders, early product managers, recent hires and advisors, and I’d drive up with a full tape recorder and plenty to think about.
But last Friday I drove down for another reason. My book The Search: How Google and Its Rivals Rewrote the Rules of Business and Transformed Our Culture, has just come out, and much to my astonishment, Google invited me down to give a talk. While Google staffers were extremely generous with their time, the fact remained that the book told the story as I heard it from many different sources, inside and outside the company. And on my own Searchblog, where I cover search and its implications, I've been known to call Google out as often as I offer praise.
As I drove down, I fretted over any number of things. Who might show up for the talk (what if no one did?!). What mistakes might be pointed out - flaws in my reporting, my writing, or my conclusions? What if the famously combative Google culture turned on me?
I needn’t have worried. My host Karen Wickre, whom I’ve known since my days as a cub reporter at MacWeek, met me at the door, and before I could make my way to the lecture hall, a clutch of friendly folks had surrounded me. Once there I saw Louis Monier, founder of Alta Vista and the star of Chapter Three, who had recently left eBay to join Google. And Peter Norvig, Google’s director of search quality, who helped me understand Google’s core search service and even presented at my Web 2.0 conference last year. And many more, many of whom I had spoken to, but most of whom I had never met.
I began by explaining how I came to write the book, a three-year odyssey which started with a link, back in late 2001, to Google’s first Zeitgeist. I read how I came to the idea of the Database of Intentions, and I read some funny emails from webmasters who had encountered the early BackRub crawler. And because it was clear the audience wanted to ponder the future of the company they had joined, I read from the chapter entitled “Google Today, Google Tomorrow.”
The best part, by far, was the Q&A that followed. Googlers are some of the most sincere questioners I've ever encountered. The exchange felt very much like conversations I've had with graduate students when I was teaching at Berkeley - no agendas, just a desire to challenge and to learn. Afterward folks lined up to have me sign their books. As the line dwindled, I looked behind me and there was Eric Schmidt, who more than any other source went out of his way to lend me his time and insights. He shook my hand and thanked me for coming, and I have to say, I was honored by the gesture. I did my best to be fair in the book, but it's never easy to read about yourself, to be the subject of someone else's conclusions. The same could be said of the entire Google team who came to listen and to converse, and I'm truly grateful for the experience.
Copyright © 2006 Google Inc. All rights reserved.
Privacy Policy -
Terms of Service
We Love Feedback
Do you want to comment on a post?Send us some email.
Google Blog is powered by Blogger. Start your own weblog.